前天我們得到一個 時間複雜度的最長嚴格遞增子序列演算法,其中
輸入序列長度、
LIS 的長度、
處理器的數量。但這個演算法在
很小的時候不是最優的。為了理解什麼是「好的平行化」,我們試圖給出一個客觀的定義 -- Work Optimality。
如果一個演算法 A 的非平行版本,其執行時間複雜度是 ,而平行化後的演算法 PA 使用
個處理器後的時間複雜度是
。我們說這個演算法 PA 相對於演算法 A 是 Work Optimal 的,若且唯若
。也就是說,給定
個處理器以後,我們可以把總工作量平均分配到
個處理器上。
回頭檢視 LIS 的演算法,傳統的 LIS 演算法,依序以二分搜尋法更新 L[1..m],要花 的時間。如果我們要找到 Work Optimal 的平行演算法,則要把我們的目標設立在 O(n log n / p) 的時間複雜度上。
之前在討論搜索問題的時候,我們知道遞迴呼叫是一種相依性,過深不是一件好事。但是如同N皇后問題一樣,如果我們可以分支出許多遞迴呼叫,那麼還滿適合拿來平行化的。
而事實上,我們可以利用分而治之法解決 LIS 問題。要怎麼做呢?首先我們不妨假設輸入是一個 1~n 的排序(對原資料進行平行版的合併排序法可以作到 時間。)接下來進行 Divide & Conquer 步驟:
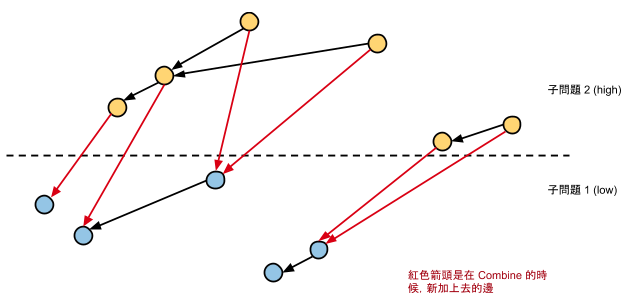
我們要做的事情就是在這張圖上更新 A 跟 P 兩個陣列的值。而這件事情相當於做拓撲排序。但是,為了作到 時間(而非昨天的
),我們必須要把圖加上一些節點,並且改造成:每個節點的 in-degree 與 out-degree 至多都是 2。(這個圖的 out-degree 本身至多是 2,因為對一個 x,要嘛直接連出去一條,要嘛連出去兩條。)
在這樣的條件下,我們就可以用類似 BFS 的方式順利在 的時間內做出 A 和 P 兩個陣列了!
第 層遞迴有
個子問題,每一個子問題的大小大約是
。因此,這層平行後所花費的總時間會是
。築層加總以後可以知道總花費時間會是
,相當接近我們想要的
了!而且若
時還保證了最壞情形下時間仍是
,很棒吧!
我們得到一個 的平行演算法,在
時是 Work-Optimal 的。我的作法是改良自 2013 年的這篇 paper:https://www.sciencedirect.com/science/article/pii/S0020019013000902 。
明天我們要轉移目標到下一個計算模型了~


 iThome鐵人賽
iThome鐵人賽